
Avec la rentrée, un grand nombre d’outils pour les SEOs pointent le bout de leur nez (et je vais également y aller de mon outil d’ici quelques semaines^^), et parmi ceux-là, il y a des bonnes surprises.
Depuis quelques mois, j’ai l’occasion de discuter avec un développeur-webmaster, que je vais appeler ici Monsieur X, sur de nombreuses problématiques algorithmiques. Et pendant l’été, Monsieur X m’a fait une démo de son nouvel outil (disponible en beta sur le site 1.fr). Mon objectif ici n’est pas de faire de la retape pour cet outil, qui est à mon avis un bel outil, mais de vous parler de ce que j’ai pu retirer des données que Monsieur X a bien voulu me donner.
D’abord, une présentation rapide de 1.fr
Une fois inscrit sur 1.fr, vous pouvez renseigner l’URL de votre site, et définir un niveau de profondeur de crawl et une quantité de pages à crawler. Une fois que c’est fait, l’outil va vous donner plusieurs types de mesures, qui vont vous permettre de qualifier votre contenu.
1.fr est essentiellement un outil qui manipule la notion de champ lexical. Visiblement, un énorme crawl du web francophone a été effectué et a permis de créer des tables de co-occurences et de proximité d’usage entre mots. Cela permet de calculer l’adéquation d’un contenu au champ lexical d’une expression. J’ai eu l’occasion de tester l’outil, voici par exemple ce qu’il donne sur une partie des pages de l’excellente rubrique cinéma du site krinein.
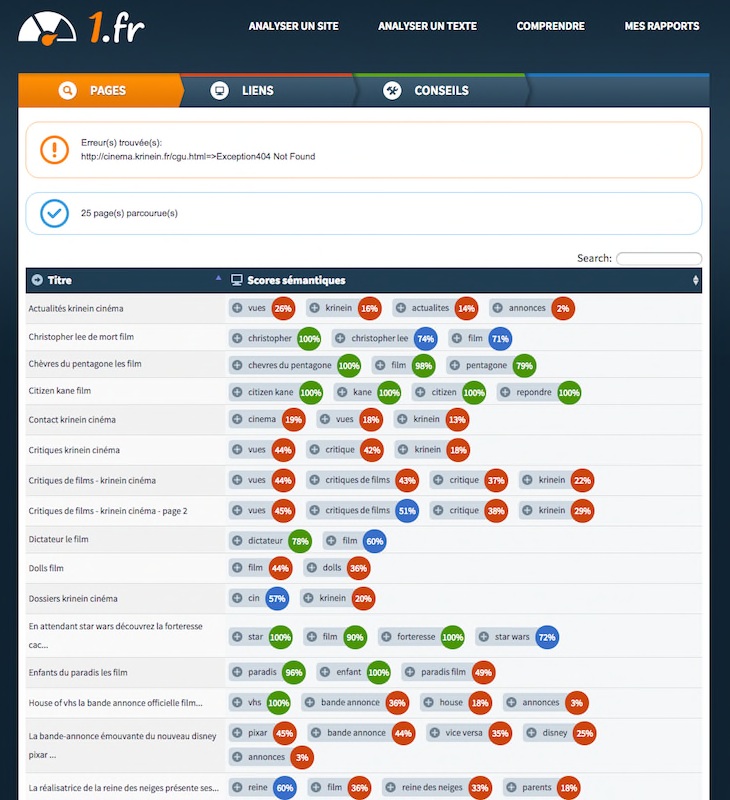 Avec les indicateurs chiffrés, on peut facilement vérifier la proximité entre le contenu et le champ lexical, et quand le chiffre est un peu faible, en cliquant sur le « + », on a des informations utiles qui apparaissent.
Avec les indicateurs chiffrés, on peut facilement vérifier la proximité entre le contenu et le champ lexical, et quand le chiffre est un peu faible, en cliquant sur le « + », on a des informations utiles qui apparaissent.
On peut faire le même type d’analyse sur les liens, avec une information sur la connexion sémantique entre la page cible et la page source (allez essayer, c’est parfois assez bluffant de voir que les connexions peuvent être très tordues). Enfin, une dernière fonctionnalité est de faire des suggestions d’adéquation entre titre et contenu.
1.fr propose également un outil supplémentaire très intéressant : le calcul du score sémantique sur un texte qui est donné en entrée à l’outil. Cela permet de tester les textes pour savoir si le contenu est à la hauteur des espérances (vous achetez des textes ? essayez donc de les passer dans l’outil).
 Bref, un outil qui donne des infos importantes sur vos contenus. Mais ce qui vous intéresse le plus aujourd’hui, c’est la suite de ce billet 😉
Bref, un outil qui donne des infos importantes sur vos contenus. Mais ce qui vous intéresse le plus aujourd’hui, c’est la suite de ce billet 😉
Analyse de la correspondance entre champ lexical et positionnement
J’ai eu la chance de recevoir de la part de Monsieur X un gros blocs de données bien utiles. Voilà ma base de travail :
- Les informations de score sémantique pour plus de 4,6 millions de pages, toutes thématiques, avec en plus les informations de positionnement (toutes ces pages sont sur la première page des SERPs Google) sur des requêtes spécifiques.
- La même chose mais pour des blocs de pages correspondant à des requêtes avec un grand nombres d’annonceurs, avec un nombre moyen et un nombre faible.
- La même chose mais pour les CPC au dessous de 0,1, pour les CPC entre 0,1 et 0,5, puis pour les CPC au dessus de 0,5.
- Les infos de score sémantique sur presque 5 millions de pages, mises en regard avec le niveau de concurrence des requêtes. Cela permet d’avoir le score sémantique moyen pour une requête pour toutes les pages d’un même niveau de concurrence.
- La même chose par volume de recherche annuel.
- Toutes les infos pour deux ensembles de requêtes de deux thématiques différentes. Le premier bloc ne contient que des requêtes qui contiennent le mot « assurance », le deuxième des requêtes avec le mot « tarif ».
Pour travailler ces données, j’ai utilisé les grands classiques :
- Corrélation de Pearson quand les valeurs avaient une importance et pour voir si il y a une corrélation affine.
- Corrélation de Spearman quand je m’intéressais à corréler les rangs.
- Estimateur de l’intervalle de confiance en fonction de la taille de l’échantillon (pour savoir si certaines conclusions sont réelles ou dues au hasard). La formule que j’utilise est le grand classique qui utilise la fonction de répartition de la loi normale centrée réduite. Ici pas besoin d’utiliser la borne de Chernoff, ce qui permet d’avoir des échantillons plus petits pour un intervalle de confiance raisonnable.
Les conclusions (un peu en vrac, mais bon)
- Il y a de grandes variations selon les thématiques et les requêtes. Par exemple, sur mon groupe « tarif », la moyenne des scores thématiques est autour de 34,19 avec un minimum à 0,44 et un maximum à 93,95. Sur la thématique « assurance », on une moyenne a presque 35, un minimum à 0,52 et un max à 100. La différence sur la moyenne est significative, ainsi que celle sur le max (mais pas celle sur le min). Dans le cas présent, on peut dire que les contenus « assurance » de la première page des SERPs sont en moyenne plus optimisés que ceux de la thématique « tarif » (quelle surprise 😉 !).
- Dans tous les cas, il y a une corrélation de Pearson négative qui va de moyenne à bonne entre score sémantique et positionnement : quand le score sémantique augmente, le positionnement descend (=il approche de la première position, le plus bas est le mieux, la position 1 est mieux que la position 10) et réciproquement (attention : corrélation, causalité, etc.).
- Il y a une corrélation de Spearman très forte entre positionnement et rang de score sémantique : quand le rang en score sémantique augmente, c’est aussi le cas du positionnement, et réciproquement. Il semble donc qu’améliorer son score sémantique soit une bonne idée !
- Pour les autres cas, je n’ai pas pu faire mieux que garantir le bon comportement statistique pour la première place. Le premier est meilleur, en moyenne, que les suivants, en matière de score sémantique.
- Ca a l’air d’être une bonne idée, mais le résultat précédent est-il OK d’un point de vue statistiques ? Pour le global, pour les requêtes à petit nombre d’annonceurs, et pour celles à CPC faible, je peux garantir (avec les volumes étudiés) que les positions 1 et 2 sont clairement dessus en terme de score sémantique. Ce n’est pas un hasard que les deux premiers des SERPs soient plus en adéquation avec le champ lexical. Attention, on parle bien EN MOYENNE, chaque cas particulier peut être différent. Par ailleurs, cela ne veux pas dire que les autres positions soient indépendantes du contenu, on en peut juste pas garantir quoi que ce soit statistiquement avec les données étudiées.
- En terme de corrélation de Spearman, les cas nombre annonceurs faible ou moyen, et le cas CPC faible, sont moins corrélés au score sémantique. En regardant en détail les données, on s’aperçoit que c’est parce que les pages dans les dernières positions de la première page sont assez rarement classées par score sémantique. Mon hypothèse est que sur les requêtes finalement peu intéressantes pour les SEOs (qu’on repère via des indicateurs SEA faibles), seules les toutes premières pages ont été travaillé par des SEOs en terme de contenu. En revanche, dès que les indicateurs SEA montrent l’intérêt des webmasters, alors la corrélation est très proche de 1 (entre 0,95 et 0,98).
- Volume de recherche et niveau de concurrence ne sont pour ainsi dire pas corrélés au score sémantique. Ce n’est pas surprenant, la corrélation se retrouve au niveau des pages qui performent (les premières places des SERPs) mais pas ailleurs.
Voilà, vous savez tout, maintenant je vous laisse jouer avec l’outil, et si vous avez des questions concernant l’analyse des données (l’outil n’est pas le mien^^) les commentaires sont là pour ça.
interessant Sylvain, merci pour cette suggestion d outil
J’ai pas compris la phrase « La même chose par volumeniveau de conc de recherche annuel. » il y a un bug ou c’est juste moi (il est tard j’ai sommeil) ? Merci pour l’outil en phase beta, je suis en train de tester l’interface 🙂 Et à très bientôt pour beta-tester ton outil (Guillaume n’est pas impliqué ?)
@Flo typo corrigée^^ Bien vu. Guillaume est dans le coup, ainsi que deux autres comparses (pas de secret mais on en parlera lors de la sortie, pas avant).
Il n’y a pas de corrélation entre ta requête principale et le champ lexical détecté ?
@Christian Je comprends pas ta question ? Dans les données ce que j’ai c’est le score sémantique entre la page et le champ lexical de la requête. Ensuite je corrèle score et position pour cette même requête.
Et en ANGLAIS !!!!!
Si les francais mettez un peu plus du leur dans des tools en anglais je vous jure que nous mangerions le reste du monde…. il faudrait que les gens y pensent
@Sylvain dans l’outil je n’ai pas pu entrer ma requête, du coup il teste une page, mais pas une page + une requête (même s’il m’a trouvé 100% grâce à la TITLE, mais ma requête n’est pas forcément à 100% dans ma TITLE)
Ah, tu parles de l’outil. Oui visiblement tu donnes la page et il te donne les champs lexicaux associés. Moi j’ai utilisé des données fournies directement par le dev à partir de la BDD de l’outil^^
Pour l’outil, c’est au dev qu’il faut s’adresser, il n’est pas de moi !
Tout à fait d’accord avec le Juge !
Pour l’instant c’est concluant je viens d’améliorer mon référencement de 3 positions passant de la 11éme place à la 8éme place de google.fr.